 Execution
Execution
Execute your flows and view the outcome.
Execution is a single run of a flow in a specific state.
Task Run
A task run is a single run of an individual task within an execution.
Each task run has associated data such as:
- Execution ID
- State
- Start Date
- End Date
Attempts
Each task run can have one or more attempts. Most task runs will have only one attempt, but you can configure retries for a task.
If retries have been configured, a task failure will generate new attempts until the retry maxAttempt or maxDuration threshold is hit.
Outputs
Each task can generate output data that other tasks of the current flow execution can use.
These outputs can be variables or files that will be stored inside Kestra's internal storage.
Outputs are described on each task documentation page and can be seen in the Outputs tab of the Execution page.
You can read more about Outputs on the Outputs page.
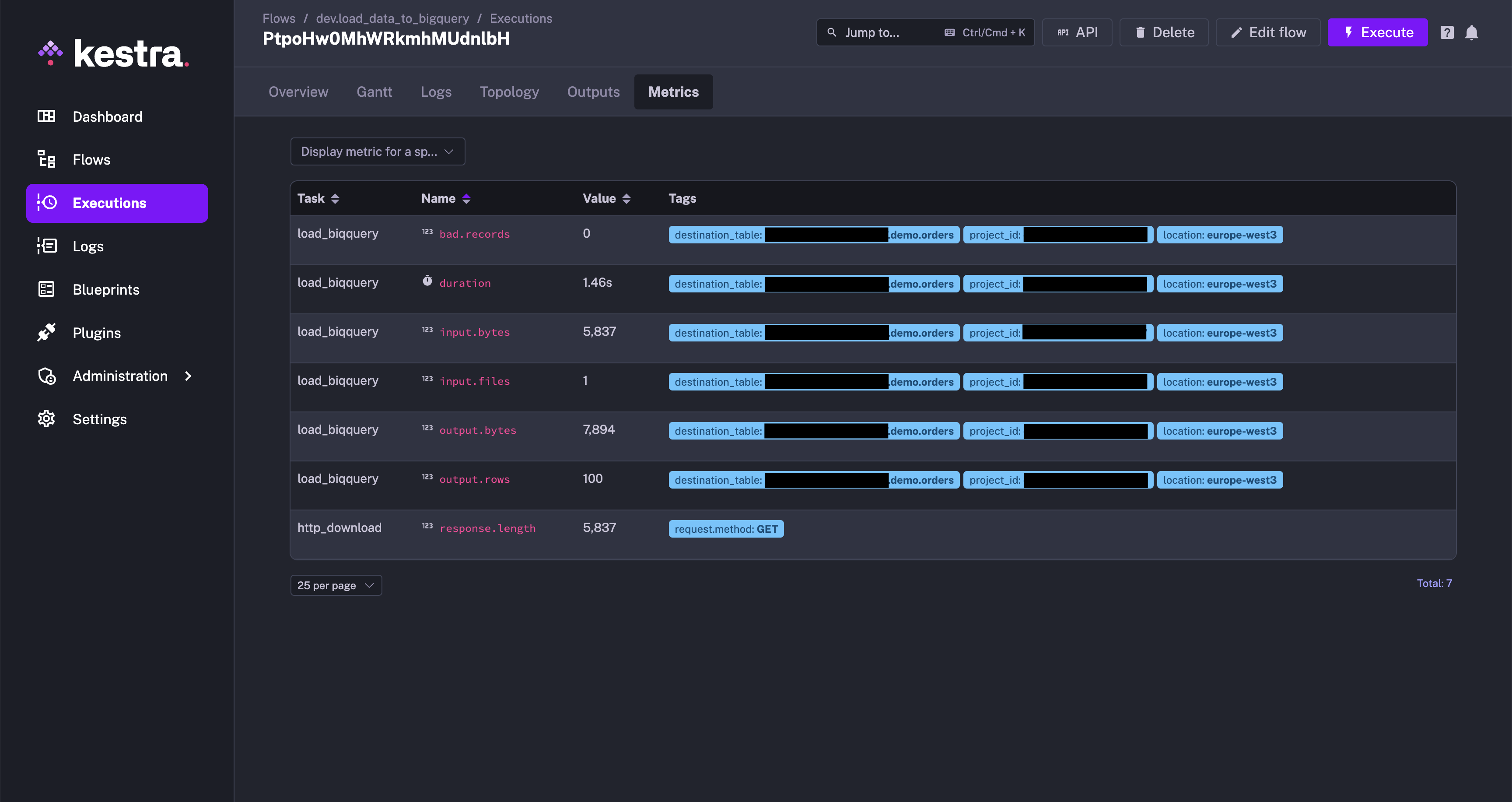
Metrics
Each task can expose metrics that may be useful in understanding the internals of a task. Metrics may include, file size, number of returned rows, or query duration. You can view the available metrics for a task type on its documentation page.
Metrics can be seen in the Metrics tab of the Executions page.
Below is an example of a flow generating metrics:
id: load_data_to_bigquery
namespace: company.team
tasks:
- id: http_download
type: io.kestra.plugin.core.http.Download
uri: https://huggingface.co/datasets/kestra/datasets/raw/main/csv/orders.csv
- id: load_biqquery
type: io.kestra.plugin.gcp.bigquery.Load
description: Load data into BigQuery
autodetect: true
csvOptions:
fieldDelimiter: ","
destinationTable: kestra-dev.demo.orders
format: CSV
from: "{{ outputs.http_download.uri }}"
We can see the list of metrics that the BigQuery Load task type will generate in the documentation here.
After executing the flow, you can see the metrics generated by the BigQuery Load task in the Metrics tab.
State
An Execution or a Task Run can be in a particular state.
There are multiple possible states:
| State | Description |
|---|---|
CREATED | The Execution or Task Run is waiting to be processed. This state usually means that the Execution is in a queue and is yet to be started. |
RUNNING | The Execution or Task Run is currently being processed. |
PAUSED | The Execution or Task Run has been paused. This status is used for two reasons: Manual validation and Delay (for a specified duration before continuing the execution). |
SUCCESS | The Execution or Task Run has been completed successfully. |
WARNING | The Execution or Task Run exhibited unintended behavior, but the execution continued and was flagged with a warning. |
FAILED | The Execution or Task Run exhibited unintended behavior that caused the execution to fail. |
KILLING | A command was issued that asked for the Execution or Task Run to be killed. The system is in the process of killing the associated tasks. |
KILLED | An Execution or Task Run was killed (upon request), and no more tasks will run. |
RESTARTED | This status is transitive. It is the same as CREATED, but for a flow that has already been executed, failed, and has been restarted. |
CANCELLED | An Execution or Task Run has been aborted because it has reached its defined concurrency limit. The limit was set to the CANCEL behavior. |
QUEUED | An Execution or Task Run has been put on hold because it has reached its defined concurrency limit. The limit was set to the QUEUE behavior. |
RETRYING | The Execution or Task Run is currently being retried. |
RETRIED | An Execution or Task Run exhibited unintended behavior, stopped, and created a new execution as defined by its flow-level retry policy. The policy was set to the CREATE_NEW_EXECUTION behavior. |
For a detailed overview of how each Execution and Task Run transition through different states, see the States page.
Execution expressions
There are a number of execution expressions which you can use inside of your flow.
| Parameter | Description |
|---|---|
{{ execution.id }} | The execution ID, a generated unique id for each execution. |
{{ execution.startDate }} | The start date of the current execution, can be formatted with {{ execution.startDate | date("yyyy-MM-dd HH:mm:ss.SSSSSS") }}. |
{{ execution.originalId }} | The original execution ID, this id will never change even in case of replay and keep the first execution ID. |
You can read more about them on the expressions page.
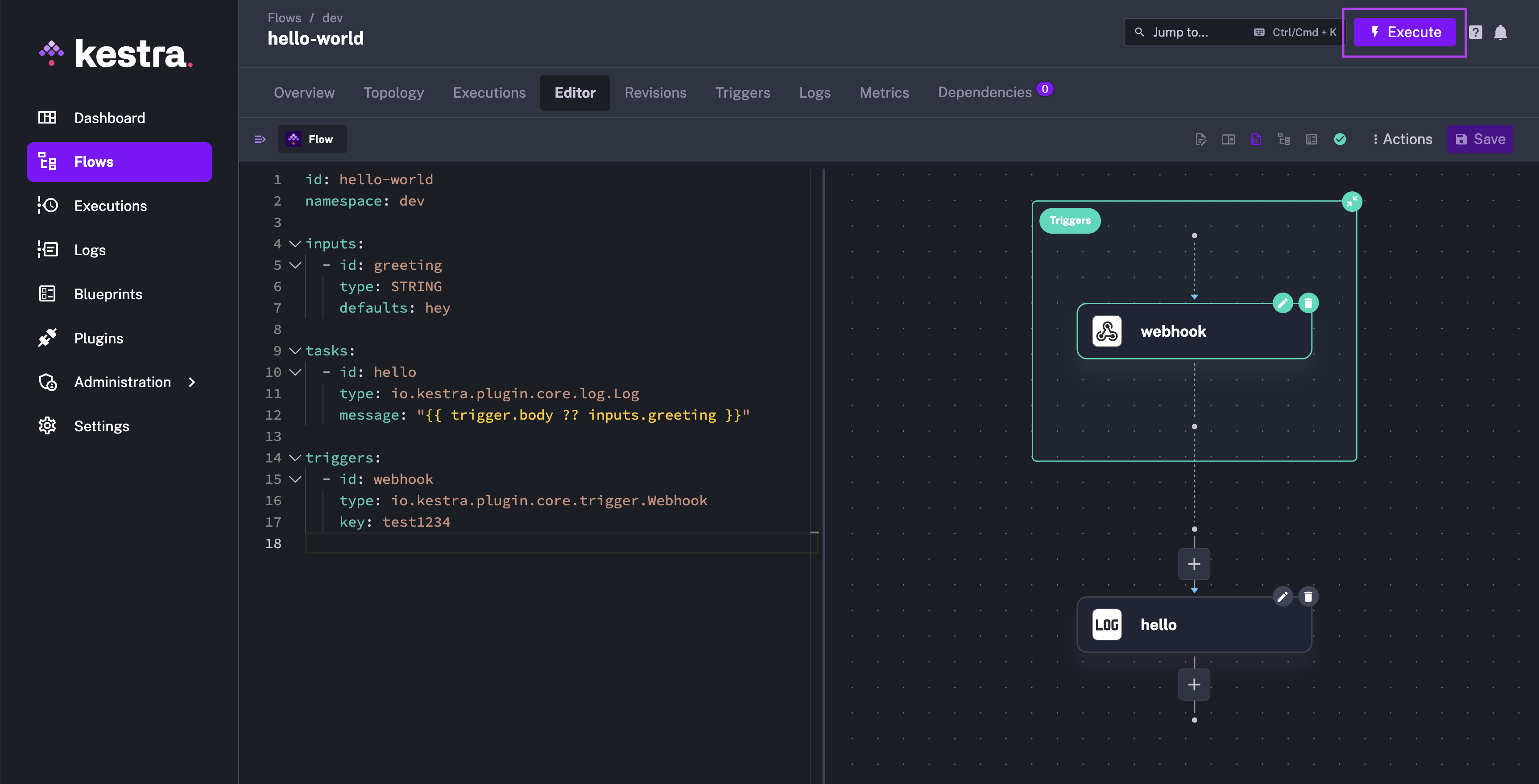
Execute a flow from the UI
You can trigger a flow manually from the Kestra UI by clicking the Execute button on the flow's page. This is useful when you want to test a flow or run it on demand.
Use automatic triggers
You can add a Schedule trigger to automatically launch a flow execution at a regular time interval.
Alternatively, you can add a Flow trigger to automatically launch a flow execution when another flow execution is completed. This pattern is particularly helpful when you want to:
- Implement a centralized namespace-level error handling strategy, e.g. to send a notification when any flow execution fails in a production namespace. Check the Alerting & Monitoring section for more details.
- Decouple your flows by following an event-driven pattern, in a backwards direction (backwards because the flow is triggered by the completion of another flow; this is in contrast to the subflow pattern, where a parent flow starts the execution of child flows and waits for the completion of each of them).
Lastly, you can use the Webhook trigger to automatically launch a flow execution when a given HTTP request is received. You can leverage the {{ trigger.body }} variable to access the request body and the {{ trigger.headers }} variable to access the request headers in your flow.
To launch a flow and send data to the flow's execution context from an external system using a webhook, you can send a POST request to the Kestra API using the following URL:
http://<kestra-host>:<kestra-port>/api/v1/executions/webhook/<namespace>/<flow-id>/<webhook-key>
Here is an example:
http://localhost:8080/api/v1/executions/webhook/dev/hello-world/secretWebhookKey42
You can also pass inputs to the flow using the inputs query parameter.
Execute a flow via an API call
You can trigger a flow execution by calling the API directly. This is useful when you want to start a flow execution from another application or service.
Let's use the following flow as example:
id: hello_world
namespace: company.team
inputs:
- id: greeting
type: STRING
defaults: hey
tasks:
- id: hello
type: io.kestra.plugin.core.log.Log
message: "{{ inputs.greeting }}"
triggers:
- id: webhook
type: io.kestra.plugin.core.trigger.Webhook
key: test1234
Assuming that you run Kestra locally, you can trigger a flow execution by calling the /api/v1/executions/{namespace}/{flowId} endpoint. This example uses curl but you could use something else like Postman to test this too:
curl -X POST \
http://localhost:8080/api/v1/executions/company.team/hello_world
The above command will trigger an execution of the latest revision of the hello_world flow from the company.team namespace.
Execute a specific revision of a flow
If you want to trigger an execution for a specific revision, you can use the revision query parameter:
curl -X POST \
http://localhost:8080/api/v1/executions/company.team/hello_world?revision=2
Execute a flow with inputs
You can also trigger a flow execution with inputs by adding the inputs as form data (the -F flag in the curl command):
curl -X POST \
http://localhost:8080/api/v1/executions/company.team/hello_world \
-F greeting="hey there"
You can pass inputs of different types, such as STRING, INT, FLOAT, DATETIME, FILE, BOOLEAN, and more.
curl -v "http://localhost:8080/api/v1/executions/company.team/kestra-inputs" \
-H "Transfer-Encoding:chunked" \
-H "Content-Type:multipart/form-data" \
-F string="a string" \
-F optional="an optional string" \
-F int=1 \
-F float=1.255 \
-F boolean=true \
-F instant="2023-12-24T23:00:00.000Z" \
-F "files=@/tmp/128M.txt;filename=file"
Execute a flow with FILE-type inputs
You can also pass files as an input. All files must be sent as multipart form data named files with a header filename=your_kestra_input_name indicating the name of the input.
Let's look at an example to make this clearer. Suppose you have a flow that takes a JSON file as input and reads the file's content:
id: large_json_payload
namespace: company.team
inputs:
- id: myCustomFileInput
type: FILE
tasks:
- id: hello
type: io.kestra.plugin.scripts.shell.Commands
inputFiles:
myfile.json: "{{ inputs.myCustomFileInput }}"
taskRunner:
type: io.kestra.plugin.core.runner.Process
commands:
- cat myfile.json
Assuming you have a file myfile.json in the current working directory, you can invoke the flow using the following curl command:
curl -X POST -F "files=@./myfile.json;filename=myCustomFileInput" 'http://localhost:8080/api/v1/executions/company.team/large_json_payload'
We recommend this pattern if you need to pass large payloads to a flow. Passing a large payload directly in the request body (e.g. as JSON-type input or as a raw JSON webhook body) is not recommended for privacy, performance and maintenability reasons. Such large payloads would be stored directly in your Kestra's database backend, cluttering valuable storage space and leading to potential performance or privacy issues. However, if you pass it as a JSON file using a FILE-type input, it will be stored in internal storage (such as S3, GCS, Azure Blob), making it more performant and cost-effective to store and retrieve.
Execute a flow via an API call in Python
You can also use the requests library in Python to make requests to the Kestra API. Here's an example:
import io
import requests
from requests_toolbelt.multipart.encoder import MultipartEncoder
with open("/tmp/128M.txt", 'rb') as fh:
url = "http://kestra:8080/api/v1/executions/company.team/hello_world"
mp_encoder = MultipartEncoder(fields={
"string": "a string",
"int": 1,
"float": 1.255,
"datetime": "2025-04-20T13:00:00.000Z",
"files": ("file", fh, "text/plain")
})
result = requests.post(
url,
data=mp_encoder,
headers={"Content-Type": mp_encoder.content_type},
)
Webhook vs. API call
When sending a POST request to the /api/v1/executions/{namespace}/{flowId} endpoint, you can send data to the flow's execution context using inputs. If you want to send arbitrary metadata to the flow's execution context based on some event happening in your application, you can leverage a Webhook trigger.
Here is how you can adjust the previous hello_world example to use the webhook trigger instead of an API call:
id: hello_world
namespace: company.team
inputs:
- id: greeting
type: STRING
defaults: hey
tasks:
- id: hello
type: io.kestra.plugin.core.log.Log
message: "{{ trigger.body ?? inputs.greeting }}"
triggers:
- id: webhook
type: io.kestra.plugin.core.trigger.Webhook
key: test1234
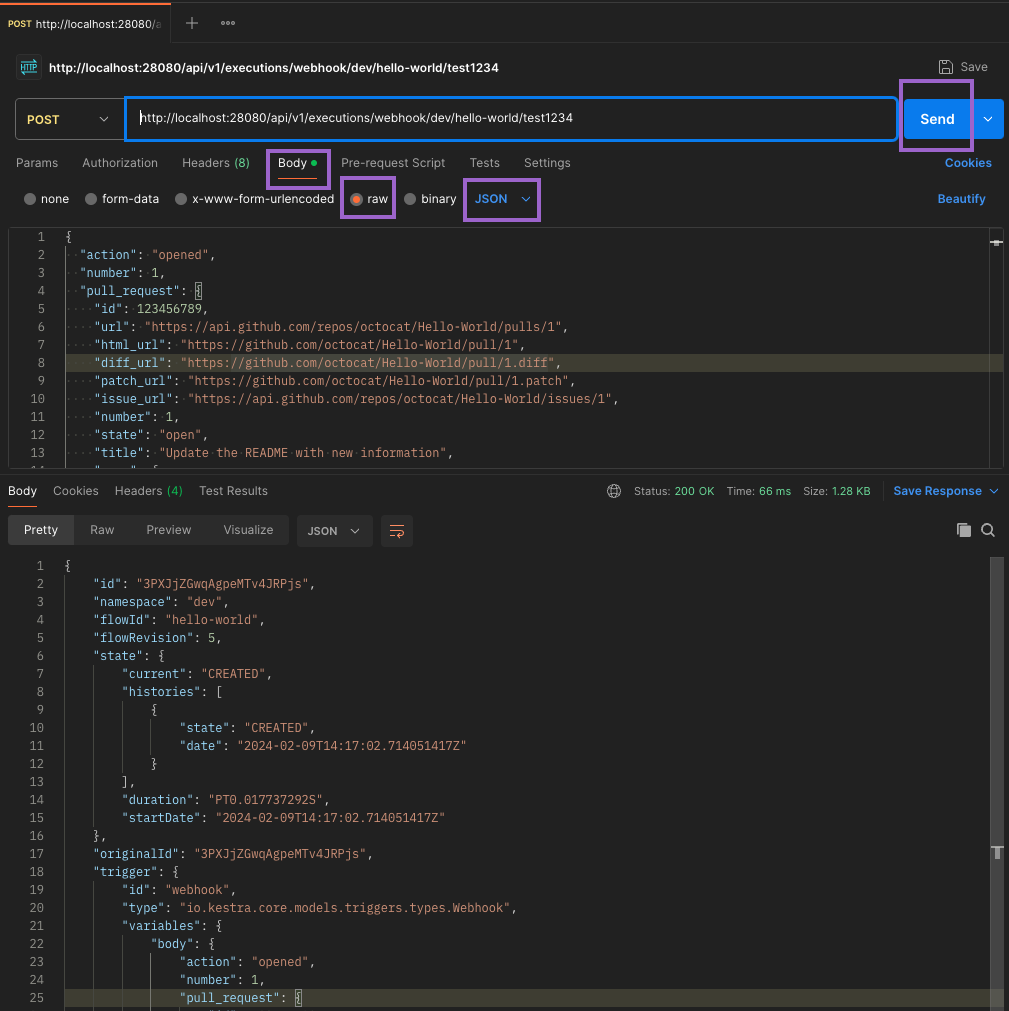
You can now send a POST request to the /api/v1/executions/webhook/{namespace}/{flowId}/{webhookKey} endpoint to trigger an execution and pass any metadata to the flow using the request body. In this example, the webhook URL would be http://localhost:8080/api/v1/executions/webhook/company.team/hello_world/test1234.
You can test the webhook trigger using a tool like Postman or cURL. Paste the webhook URL in the URL field and a sample JSON payload in the request body. Make sure to set:
- the request method to POST
- the request body type to raw and a JSON format.
Finally, click the Send button to trigger the flow execution. You should get a response with the execution ID and status code 200 OK.
⚡️ When to use a webhook trigger vs. an API call to create an Execution? To decide whether to use a webhook trigger or an API call to create an Execution, consider the following:
- Use the webhook trigger when you want to send arbitrary metadata to the flow's execution context based on some event happening in your application.
- Use the webhook trigger when you want to create new executions based on some event happening in an external application, such as a GitHub event (e.g. a Pull Request is merged) or a new record in a SaaS application, and you want to send the event metadata (header and body) to the flow to act on it.
- Use an API call to create an Execution when you don't need to send any payload (apart from
inputs) to the flow's execution context.
Execute a flow from Python
You can also execute a flow using the kestra pip package. This is useful when you want to trigger a flow execution from a Python application without creating an API request from scratch as shown in the earlier example.
First, install the package:
pip install kestra
Then, you can trigger a flow execution by calling the execute() method. Here is an example for the same hello_world flow in the namespace company.team as above:
from kestra import Flow
flow = Flow()
flow.execute('company.team', 'hello_world', {'greeting': 'hello from Python'})
Now imagine that you have a flow that takes a FILE-type input and reads the file's content:
id: myflow
namespace: company.team
inputs:
- id: myfile
type: FILE
tasks:
- id: print_data
type: io.kestra.plugin.core.log.Log
message: "file's content {{ read(inputs.myfile) }}"
Assuming you have a file called example.txt in the same directory as your Python script, you can pass a file as an input to the flow using the following Python code:
import os
from kestra import Flow
os.environ["KESTRA_HOSTNAME"] = "http://host.docker.internal:8080" # # Set this when executing this Python code inside Kestra
flow = Flow()
with open('example.txt', 'rb') as fh:
flow.execute('company.team', 'myflow', {'files': ('myfile', fh, 'text/plain')})
Keep in mind that files is a tuple with the following structure: ('input_id', file_object, 'content_type').
Execute with ForEachItem
The ForEachItem task allows you to iterate over a list of items and run a subflow for each item, or for each batch containing multiple items. This is useful when you want to process a large list of items in parallel, e.g. to process millions of records from a database table or an API payload.
The ForEachItem task is a Flowable task, which means that it can be used to define the flow logic and control the execution of the flow.
Syntax:
id: each_example
namespace: company.team
tasks:
- id: each
type: io.kestra.plugin.core.flow.ForEachItem
items: "{{ inputs.file }}" # could be also an output variable {{ outputs.extract.uri }}
inputs:
file: "{{ taskrun.items }}" # items of the batch
batch:
rows: 4
bytes: "1024"
partitions: 2
namespace: company.team
flowId: subflow
revision: 1 # optional (default: latest)
wait: true # wait for the subflow execution
transmitFailed: true # fail the task run if the subflow execution fails
labels: # optional labels to pass to the subflow to be executed
key: value
Was this page helpful?